Variant calling
Learning outcomes
After having completed this chapter you will be able to:
- Describe how variant information is stored in a variant call format (
.vcf) file - Describe the ‘missing genotype problem’ when calling variants of multiple samples, and the different methods on how this can be solved
- Follow
gatkbest practices workflow to perform a variant analysis by:- Applying Base Quality Score Recalibration on an alignment file
- Calling variants with
gatk HaplotypeCaller - Combining multiple
vcffiles into a singlevcffile
- Perform basic operations to get statistics of a
vcffile
Material
The paper on genomic variant call format (gVCF)
GATK best practices germline short variant workflow:
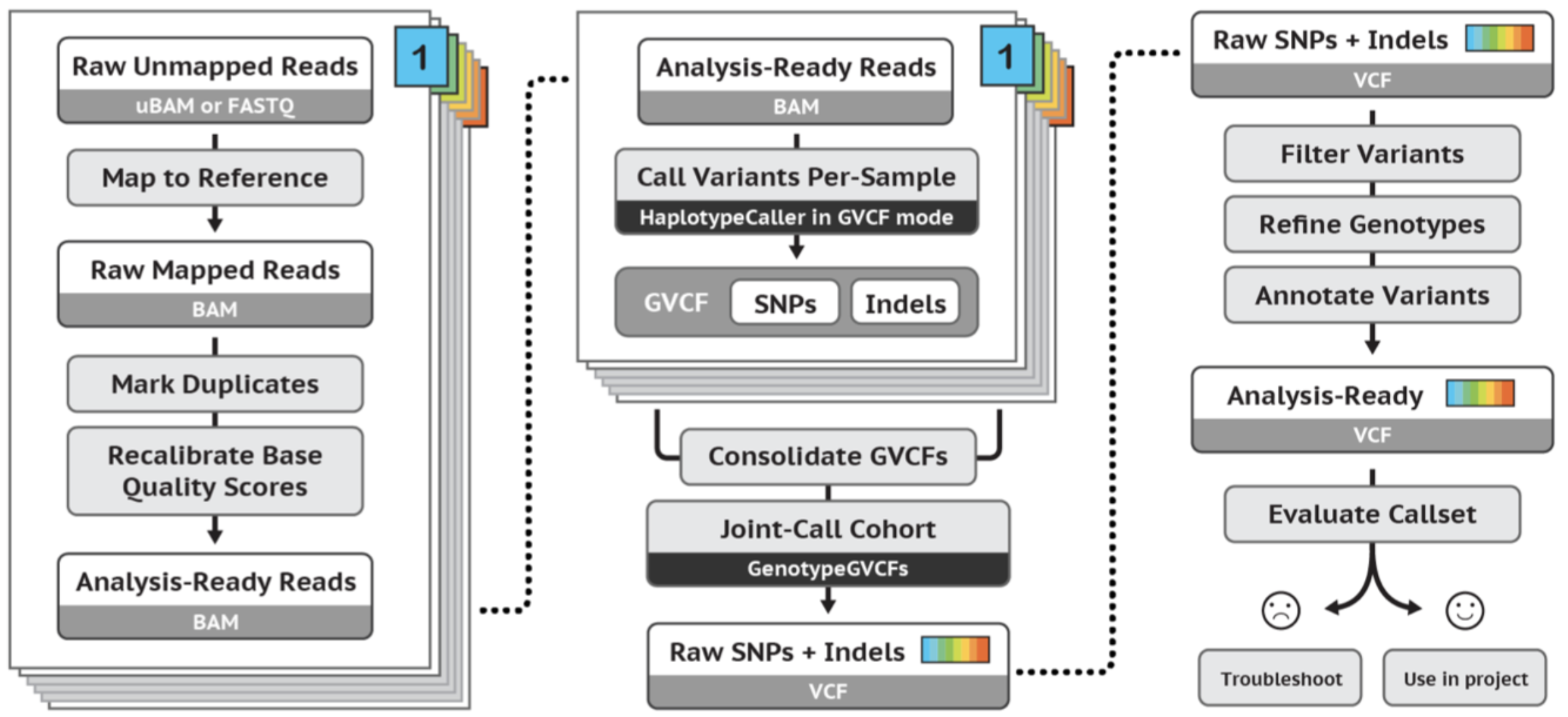
Exercises
1. Indexing, indexing, indexing
Many algorithms work faster, or only work with an index of their (large) input files. In that sense, gatk is no different from other tools. The index for a reference needs to be created in two steps:
cd ~/workdir/data/reference
samtools faidx <reference.fa>
gatk CreateSequenceDictionary --REFERENCE <reference.fa>
Also input vcf files need to be indexed. This will create a .idx file associated with the .vcf. You can do this like this:
gatk IndexFeatureFile --input <variants.vcf>
Exercise: Create the required gatk indexes for:
- The reference genome
reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa - A part of the dbsnp database:
variants/GCF.38.filtered.renamed.vcf - A part of the 1000 genomes indel golden standard:
variants/1000g_gold_standard.indels.filtered.vcf
Answer
Creating the index for the reference genome:
cd ~/workdir/data
samtools faidx reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa
gatk CreateSequenceDictionary --REFERENCE reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa
Creating the indices for the vcfs:
gatk IndexFeatureFile --input variants/1000g_gold_standard.indels.filtered.vcf
gatk IndexFeatureFile --input variants/GCF.38.filtered.renamed.vcf
Chromosome names
Unlike IGV, gatk requires equal chromosome names for all its input files and indexes, e.g. in .fasta, .bam and .vcf files. In general, for the human genome there are three types of chromosome names:
- Just a number, e.g.
20 - Prefixed by
chr. e.g.chr20 - Refseq name, e.g.
NC_000020.11
Before you start the alignment, it’s wise to check out what chromosome naming your input files are using, because changing chromosome names in a .fasta file is easier than in a .bam file.
If your fasta titles are e.g. starting with a number you can add chr to it with sed:
sed s/^>/>chr/g <reference.fasta>
You can change chromsome names in a vcf with bcftools annotate:
bcftools annotate --rename-chrs <tab-delimited-renaming> <input.vcf>
2. Base Quality Score Recalibration (BQSR)
BQSR evaluates the base qualities on systematic error. It can ignore sites with known variants. BQSR helps to identify faulty base calls, and therefore reduces the chance on discovering false positive variant positions.
BQSR is done in two steps:
- Recalibration with
gatk BaseRecalibrator - By using the output of
gatk BaseRecalibrator, the application to the bam file withgatk ApplyBQSR
Exercise: Check out the documentation of the tools. Which options are required?
Answer
For gatk BaseRecalibrator:
--reference--input--known-sites--output
For gatk ApplyBQSR:
--bqsr-recal-file--input--output
Exercise: Run the two commands with the required options on mother.rg.md.bam, with --known-sites variants/1000g_gold_standard.indels.filtered.vcf and variants/GCF.38.filtered.renamed.vcf.
Multiple inputs for same argument
In some cases you need to add multiple inputs (e.g. multiple vcf files) into the same argument (e.g. --known-sites). To provide multiple inputs for the same argument in gatk, you can use the same argument multiple times, e.g.:
gatk BaseRecalibrator \
--reference <reference.fa> \
--input <alignment.bam> \
--known-sites <variants1.vcf> \
--known-sites <variants2.vcf> \
--output <output.table>
Answer
cd ~/workdir
mkdir bqsr
gatk BaseRecalibrator \
--reference data/reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa \
--input alignment/mother.rg.md.bam \
--known-sites data/variants/GCF.38.filtered.renamed.vcf \
--known-sites data/variants/1000g_gold_standard.indels.filtered.vcf \
--output bqsr/mother.recal.table
gatk ApplyBQSR \
--input alignment/mother.rg.md.bam \
--bqsr-recal-file bqsr/mother.recal.table \
--output bqsr/mother.recal.bam
Exercise: Place these commands in a ‘for loop’, that performs the BQSR for mother, father and son.
Answer
cd ~/workdir
for sample in mother father son
do
gatk BaseRecalibrator \
--reference data/reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa \
--input alignment/$sample.rg.md.bam \
--known-sites data/variants/GCF.38.filtered.renamed.vcf \
--known-sites data/variants/1000g_gold_standard.indels.filtered.vcf \
--output bqsr/$sample.recal.table
gatk ApplyBQSR \
--input alignment/$sample.rg.md.bam \
--bqsr-recal-file bqsr/$sample.recal.table \
--output bqsr/$sample.recal.bam
done
3. Variant calling
Calculating PL and GQ by hand
Here’s a function in R to calculate genotype likelihoods as described in Li H. Bioinformatics. 2011;27:2987–93 (assuming equal base error probabilities for all reads):
genotype_likelihood <- function(m,g,e,ref,alt){
(((m-g)*e+g*(1-e))^alt * ((m-g)*(1-e)+g*e)^ref)/(m^(ref+alt))
}
Where:
m: ploidyg: number of alternative allelese: base error probabilityref: number of reference alleles countedalt: number of alternative alleles counted
Exercise: In a local R session, calculate the three genotype likelihoods (for g = 0, g = 1 and g = 2) for a case where we count 22 reference alleles and 4 alternative alleles (so a coverage of 26), and base error probability of 0.01. Calculate the PL values (-10*log10(likelihood)) for each genotype.
No local R installation?
If you don’t have access to an R installation, you can also install it in the jupyter environment by running inside the terminal:
conda install r-base
After installation, start an interactive R session by typing R.
Answer
# For g = 0 (i.e. 0 reference alleles)
-10*log10(genotype_likelihood(m = 2, g= 0, e = 0.01, ref = 22, alt = 4))
# [1] 80.96026
-10*log10(genotype_likelihood(m = 2, g= 1, e = 0.01, ref = 22, alt = 4))
# [1] 78.2678
-10*log10(genotype_likelihood(m = 2, g= 2, e = 0.01, ref = 22, alt = 4))
# [1] 440.1746
Exercise: What is the most likely genotype? What is the genotype quality (GQ)? Do you think we should be confident about this genotype call?
Answer
The most likely genotype has the lowest PL, so where g=1 (heterozygous). GL is calculated by subtracting the lowest PL from the second lowest PL, so 80.96 - 78.27 = 2.69.
This is a low genotype quality (note that we’re in the phred scale), i.e. an error probability of 0.54. This makes sense, if the genotype is heterozygous we would roughly expect to count as many reference as alternative alleles, and our example quite strongly deviates from this expectation.
Calling variants with GATK
The command gatk HaplotypeCaller is the core command of gatk. It performs the actual variant calling.
Exercise: Check out the gatk HaplotypeCaller documentation, and find out which arguments are required.
Answer
Required arguments are:
--input--ouput--reference
Exercise: Make a directory ~/workdir/variants to write the output vcf. After that, run gatk HaplotypeCaller with required options on the recalibrated alignment file of the mother (bqsr/mother.recal.bam). We’ll focus on a small region, so add --intervals chr20:10018000-10220000.
Answer
cd ~/workdir
mkdir variants
gatk HaplotypeCaller \
--reference data/reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa \
--input bqsr/mother.recal.bam \
--output variants/mother.HC.vcf \
--intervals chr20:10018000-10220000
Exercise: You can get the number of records in a vcf with piping the output of grep -v '^#' to wc -l. Get the number of variants in the vcf.
Answer
grep -v '^#' variants/mother.HC.vcf | wc -l
Shows you that there are 411 variants in there.
You can get some more statistics with gatk VariantsToTable. The output can be used to easily query things in R or MS Excel.
Here’s an example:
gatk VariantsToTable \
--variant variants/mother.HC.vcf \
--fields CHROM -F POS -F TYPE -GF GT \
--output variants/mother.HC.table
Exercise: Run the command and have a look at the first few records (use e.g. head or less). After that, report the number of SNPs and INDELs.
Answer
You can get the number of SNPs with:
grep -c "SNP" variants/mother.HC.table
which will give 326
And the number of INDELs with:
grep -c "INDEL" variants/mother.HC.table
that outputs 84
A more fancy way to this would be:
cut -f 3 variants/mother.HC.table | tail -n +2 | sort | uniq -c
Giving:
84 INDEL
1 MIXED
326 SNP
We will do the variant calling on all three samples. Later we want to combine the variant calls. For efficient merging of vcfs, we will need to output the variants as a GVCF. To do that, we will use the option --emit-ref-confidence GVCF. Also, we’ll visualise the haplotype phasing with IGV in the next section. For that we’ll need a phased bam. You can get this output with the argument --bam-output.
Exercise: Run gatk HaplotypeCaller for mother, father and son by using a loop, and by using the arguments in the previous exercise. On top of that add the arguments --emit-ref-confidence GVCF and --bamoutput <phased.bam>.
Answer
cd ~/workdir
for sample in mother father son
do
gatk HaplotypeCaller \
--reference data/reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa \
--input bqsr/$sample.recal.bam \
--output variants/$sample.HC.g.vcf \
--bam-output variants/$sample.phased.bam \
--intervals chr20:10018000-10220000 \
--emit-ref-confidence GVCF
done
4. Combining GVCFs
Now that we have all three GVCFs of the mother, father and son, we can combine them into a database. We do this because it enables us to later add GVCFs (with the option --genomicsdb-update-workspace-path), and to efficiently combine them into a single vcf.
You can generate a GenomicsDB on our three samples like this:
cd ~/workdir
gatk GenomicsDBImport \
--variant variants/mother.HC.g.vcf \
--variant variants/father.HC.g.vcf \
--variant variants/son.HC.g.vcf \
--intervals chr20:10018000-10220000 \
--genomicsdb-workspace-path genomicsdb
Exercise: Run this command to generate the database.
You can retrieve the combined vcf from the database with gatk GenotypeGVCFs.
gatk GenotypeGVCFs \
--reference data/reference/Homo_sapiens.GRCh38.dna.chromosome.20.fa \
--variant gendb://genomicsdb \
--intervals chr20:10018000-10220000 \
--output variants/trio.vcf
Exercise: Run this command to generate the combined vcf.