After having completed this chapter you will be able to:
Explain what kind of information single-cell RNA-seq (scRNA-seq) can give you to answer a biological question
Describe essential considerations during the design of a single-cell RNA-seq experiment
Describe the pros and cons of different single-cell sequencing methods
Use cellranger to:
To align reads and generate count tables
Perform basic QC on alignments and counts
Running cellranger count
The exercises below assume that you are enrolled in the course, and have access to the server. These exercises are not essential to run for the rest of the course, so you can skip them. If you want to do them anyway, you can try to install cellranger locally (only on Linux or WSL). In addition, you will need to download the references. You can get it by with this code (choose your OS):
Cloud server/Linux/MacOS/WSL
Run the following commands in the terminal or other command line prompt application:
wget https://single-cell-transcriptomics.s3.eu-central-1.amazonaws.com/cellranger_index.tar.gz
tar -xvf cellranger_index.tar.gz
rm cellranger_index.tar.gz
Windows (only relevant if working locally)
If you are working on the cloud server, follow the instructions above. Download using the link, and unpack in your working directory. This will download and extract the index in the current directory. Specify the path to this reference in the exercises accordingly.
Data overview
Have a look in the directory course_data/reads and cellranger_index. In the reads directory you will find reads on one sample: ETV6-RUNX1_1. In the analysis part of the course we will work with six samples, but due to time and computational limitations we will run cellranger count on one of the samples, and only reads originating from chromsome 21 and 22.
The input you need to run cellranger count are the sequence reads and a reference. Here, we have prepared a reference only with chromosome 21 and 22, but in ‘real life’ you would of course get the full reference genome of your species. The reference has a specific format. You can download precomputed human and mouse references from the 10X website. If your species of interest is not one of those, you will have to generate it yourself. For that, have a look here.
To be able to run cellranger in the compute environment, first run:
export PATH=/data/cellranger-8.0.1:$PATH
Have a look at the documentation of cellranger count (scroll down to Command-line argument reference).
You can find the input files here:
reads: course_data/reads/ (from the downloaded tar package in your home directory)
pre-indexed reference: cellranger_index
Exercise 1: Fill out the missing arguments (at FIXME) in the script below, and run it:
Have a look out the output directory (i.e. ~/ETV6-RUNX1_1/outs). The analysis report (web_summary.html) is usually a good place to start.
Exercise 2: Have a good look inside web_summary.html. Anything that draws your attention? Is this report good enough to continue the analysis?
Not really. First of all there is a warning: Fraction of RNA read bases with Q-score >= 30 is low. This means that there is a low base quality of the reads. A low base quality gives results in more sequencing error and therefore possibly lower performance while mapping the reads to genes. However, a Q-score of 30 still represents 99.9% accuracy.
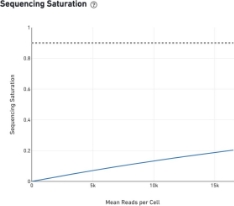
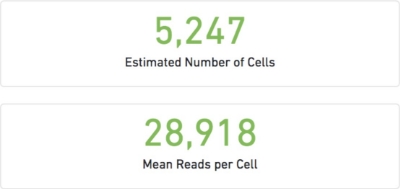
What should worry us more is the number of reads per cell (363) and the sequencing saturation (7.9%). In most cases you should aim for 30.000 - 50.000 reads per cell (depending on the application). We therefore don’t have enough reads per cell. However, as you might remember, this was a subset of reads (1 million) mapped against chromosome 21 & 22, while the original dataset contains 210,987,037 reads. You can check out the original report at course_data/count_matrices/ETV6-RUNX1_1/outs/web_summary.html.
For more info on sequencing saturation, have a look here.
Understanding the CellRanger output
The run summary from cellranger count can be viewed by clicking “Summary” in the top left corner. The summary metrics describe sequencing quality and various characteristics of the detected cells. Similar web summaries are also output from the cellranger reanalyze and cellranger aggr pipelines.
This report will serve you as first-line feedback on how the experiment went. It provides an easily accessible summary to scrutinize the success of the experiment.
It will help answering the questions like:
What is the quality of the run?
How many cells do you have?
Is the cell count estimate credible?
Was the sample sequenced deep enough? Where the cells intact and well?
Is the quality of the cells uniform?
Note that some of these questions will be more definitively answered during a successive (more hands-on) part of quality control (QC) process. Consider this just the beginning of the scrutiny.
Basic QC metrics
The number of cells detected, the mean reads per cell, and the median genes detected per cell are prominently displayed near the top of the page.
Estimated Cell number: This is determined from the number of cell barcodes with a ‘reasonable’ numbers of observations. This number is an estimate because there is no binary flag “full/empty” that tell us if a droplet had a cell inside or not. Every droplet will enter in contact with some free-floating RNA, therefore some threshold needs to be set to cell-associated barcodes vs noise from empty GEMs. However, this threshold cannot be a fixed number as it will depend on the overall quality of the experiment, size of the cells and depth of the sequences and mis-called sequences. So, this number automatically estimated from the “Barcode Rank Plot” that we will see below.
Note: this number is estimated using the thresholds to cellranger count as a bias, if the threshold is changed the count can give different predictions, and in some cases it will be necessary to do so. For example: to account for a not-so-successful experiment with high level of free-floating mRNA in the input cell suspension or a lysis caused mixing the RT mix with the cell suspension.
Mean Read per cell: This is the mean of sequencing reads that is obtained on average to the cells. Note that this refers only to the ones counted in “Estimated number of cells” and therefore:
Also note that this number DOES NOT correspond to the number of UMI per cells (the value that is actually used for the analysis).
Exercise 3: On the basis of what learned in the lectures and above, can you explain how “Mean Reads per cell” and “UMI count” are related? How is “UMI count” obtained by the pipeline? Will doubling the number of reads double the number of UMIs?
The mean reads per cell is the number of FASTQ READS containing a cell barcode assigned to a particular cell. The UMI count is the number of unique RNA MOLECULES that were sequenced assigned to a particular gene and cell. The cellranger pipeline determines the UMI count using the UMI barcode, which is different from the cell barcode. The UMI barcode is unique to each distinct RNA molecule in a cell. So, there is a possibility of multiple reads containing the same UMI barcode and being “collapsed” into a single count for the UMI count.
Doubling the number of reads will likely increase the number of UMIs, due to the detection of new RNA molecules with increased sequencing depth, but it will not double the number of UMIs because many additional reads will be assigned to the same RNA/UMI barcode.
Diagnostics
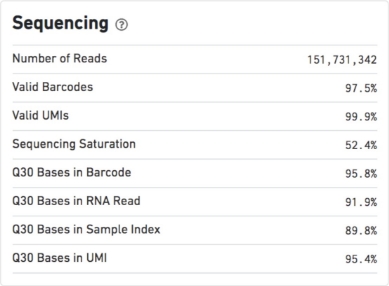
QC metrics – Sequencing
Number of Reads
Total number of read pairs that were assigned to this library in demultiplexing.
Valid Barcodes
Fraction of reads with barcodes that match the whitelist after barcode correction.
Sequencing Saturation
The fraction of reads originating from an already-observed UMI. This is a function of library complexity and sequencing depth. More specifically, this is the fraction of confidently mapped, valid cell-barcode, valid UMI reads that had a non-unique (cell-barcode, UMI, gene). This metric was called “cDNA PCR Duplication” in versions of Cell Ranger prior to 1.2.
Q30 Bases in Barcode
Fraction of cell barcode bases with Q-score >= 30, excluding very low quality/no-call (Q <= 2) bases from the denominator.
Q30 Bases in RNA Read
Fraction of RNA read bases with Q-score >= 30, excluding very low quality/no-call (Q <= 2) bases from the denominator. This is Read 1 for the Single Cell 3’ v1 chemistry and Read 2 for the Single Cell 3’ v2 chemistry.
Q30 Bases in Sample Index
Fraction of sample index bases with Q-score >= 30, excluding very low quality/no-call (Q <= 2) bases from the denominator.
Q30 Bases in UMI
Fraction of UMI bases with Q-score >= 30, excluding very low quality/no-call (Q <= 2) bases from the denominator.
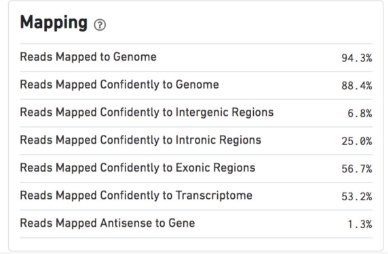
QC metrics – Mapping
Reads Mapped to Genome
Fraction of reads that mapped to the genome.
Reads Mapped Confidently to Genome
Fraction of reads that mapped uniquely to the genome. If a gene mapped to exonic loci from a single gene and also to non-exonic loci, it is considered uniquely mapped to one of the exonic loci.
Reads Mapped Confidently to Intergenic Regions
Fraction of reads that mapped uniquely to an intergenic region of the genome.
Reads Mapped Confidently to Intronic Regions
Fraction of reads that mapped uniquely to an intronic region of the genome.
Reads Mapped Confidently to Exonic Regions
Fraction of reads that mapped uniquely to an exonic region of the genome.
Reads Mapped Confidently to Transcriptome
Fraction of reads that mapped to a unique gene in the transcriptome. The read must be consistent with annotated splice junctions. These reads are considered for UMI counting.
Reads Mapped Antisense to Gene
Fraction of reads confidently mapped to the transcriptome, but on the opposite strand of their annotated gene. A read is counted as antisense if it has any alignments that are consistent with an exon of a transcript but antisense to it, and has no sense alignments.
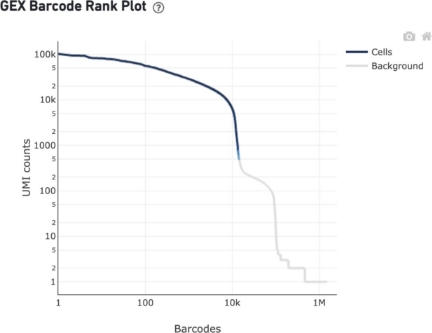
Ranked Barcode Plot
The Barcode Rank Plot under the “Cells” dashboard shows the distribution of barcode counts and which barcodes were inferred to be associated with cells. It is one of the most informative QC plots, it enables one to assess sample quality and to formulate hypothesis of what might have gone wrong if the experiment was not perfectly successful.
To obtain this plot, reads are grouped by barcode, the number of UMI is counted, resulting in a vector of UMI count per barcode (note: one barcode - one GEM!). The counts are then sorted and the vector is displayed in rank vs counts plot:
The y-axis is the number of UMI counts mapped to each barcode and the x-axis is the number of barcodes below that value.
Note that due to the high number of GEMs with at least one UMI the only way to visualize all the data is a log-log axes plot.
How does one interpret the plot? What to expect?
Ideally there is a steep dropoff separating high UMI count cells from low UMI count background noise:
A steep drop-off is indicative of good separation between the cell-associated barcodes and the barcodes associated with empty partitions.
Barcodes can be determined to be cell-associated based on their UMI count or by their RNA profiles, therefore some regions of the graph can contain both cell-associated and background-associated barcodes.
The color of the graph represents the local density of barcodes that are cell-associated.
In fact, the cutoff is determined with a two-step procedure:
It uses a cutoff based on total UMI counts of each barcode to identify cells. This step identifies the primary mode of high RNA content cells.
Then the algorithm uses the RNA profile of each remaining barcode to determine if it is an “empty” or a cell containing partition. This second step captures low RNA content cells, whose total UMI counts may be similar to empty GEMs.
Saturation - is there a gain in sequencing more?
The sequencing saturation plot allows the user to assess the relative tradeoffs of sequencing deeper or shallower. As sequencing saturation increases, the total number of molecules detected in the library increases, but with diminishing returns as saturation is approached.
A good rule of thumb for most cell types is that: An average of 40k reads per cell is a minimal sufficient that with 80k reads being usually an excellent depth. There is certainly gain in sequencing more but it is not cost-effective in general. So, it is important to evaluate if going deeper has a value to your scientific question.
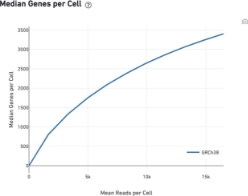
Analysis view
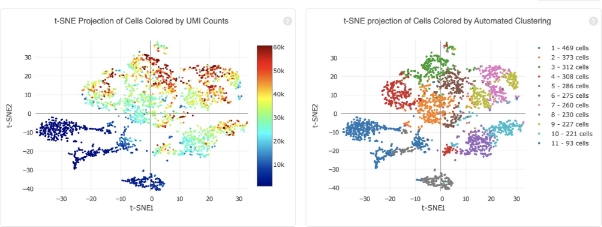
The automated secondary analysis results can be viewed by clicking “Analysis” in the top left corner. The secondary analysis provides the following:
A dimensional reduction analysis which projects the cells into a 2-D space (t-SNE), including an automated clustering analysis which groups together cells that have similar expression profiles.
A list of genes that are differentially expressed between the selected clusters
Plots showing the effect of decreased sequencing depth on observed library complexity and on median genes per cell detected
Troubleshooting: when things go bad
For other situations like these two below, there is usually little you can do and you’d better contact 10X genomics support and/or the sequencing core facility at your institution
Exercise 4: We provide you with some web_summary.html files. Use what you have learned above to evaluate each one of the experiments and write a short evaluation of what you observe at least ~50 words per each file. When you write a short summary, imagine you are reporting to your supervisor about how the experiment went.
Click the links and type Ctrl+S (Windows) or Cmd+S (Mac) to save the file to your computer. After that, open them in your browser.
 Then the algorithm uses the RNA profile of each remaining barcode to determine if it is an “empty” or a cell containing partition. This second step captures low RNA content cells, whose total UMI counts may be similar to empty GEMs.
Then the algorithm uses the RNA profile of each remaining barcode to determine if it is an “empty” or a cell containing partition. This second step captures low RNA content cells, whose total UMI counts may be similar to empty GEMs.