Cell annotation
Material
Exercises
Load the following packages:
In the last exercise we saw that probably clustering at a resolution of 0.3 gave the most sensible results. Let’s therefore set the default identity of each cell based on this clustering:
seu <- Seurat::SetIdent(seu, value = seu$RNA_snn_res.0.3)From now on, grouping (e.g. for plotting) is done by the active identity (set at @active.ident) by default.
During cell annotation we will use the original count data (not the integrated data):
DefaultAssay(seu) <- "RNA"Based on the UMAP we have generated, we can visualize expression for a gene in each cluster:
Seurat::FeaturePlot(seu, "HBA1")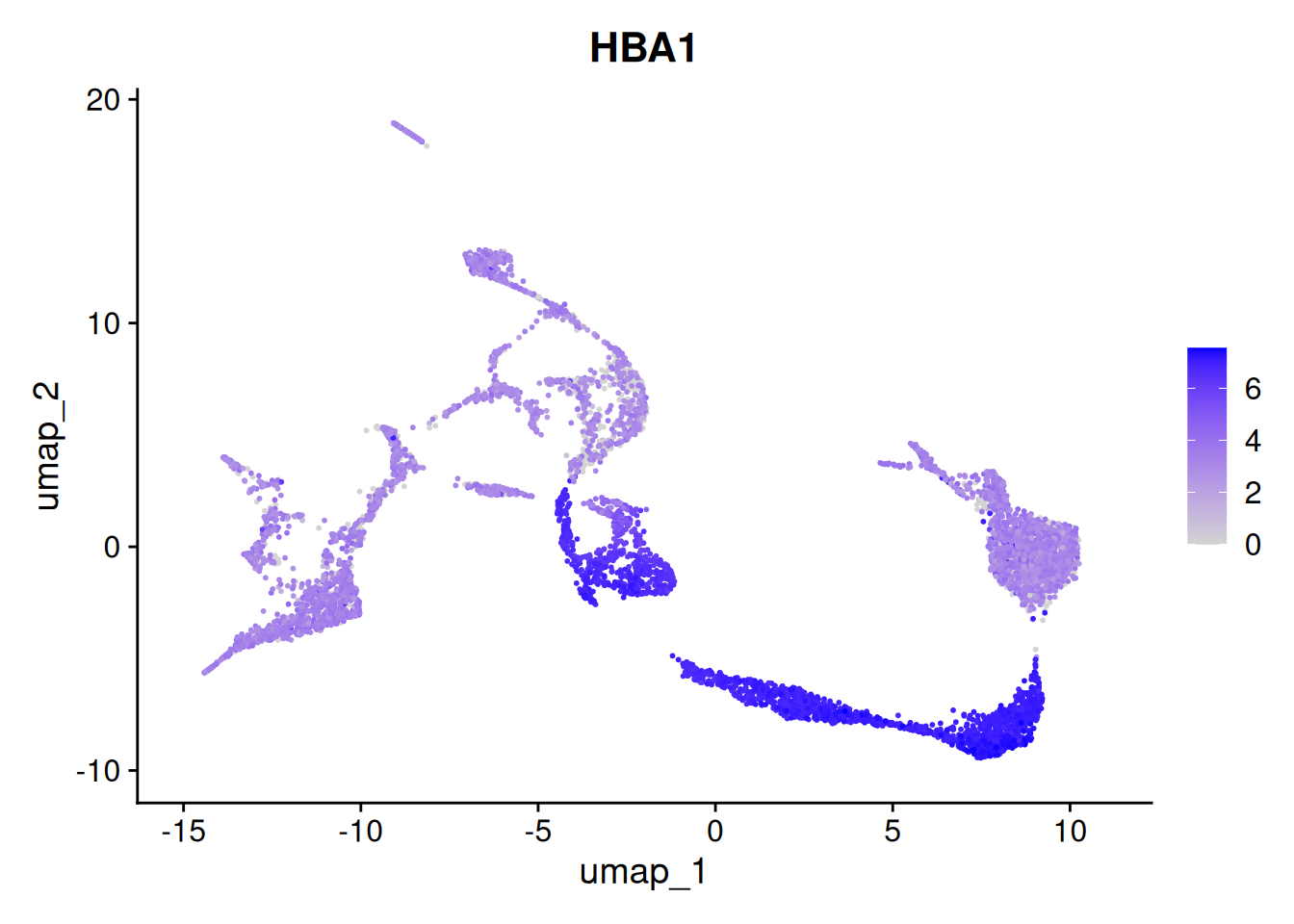
Based on expression of sets of genes you can do a manual cell type annotation. If you know the marker genes for some cell types, you can check whether they are up-regulated in one or the other cluster. Here we have some marker genes for two different cell types:
Let’s have a look at the expression of the four T cell genes:
Seurat::FeaturePlot(seu, tcell_genes, ncol=2)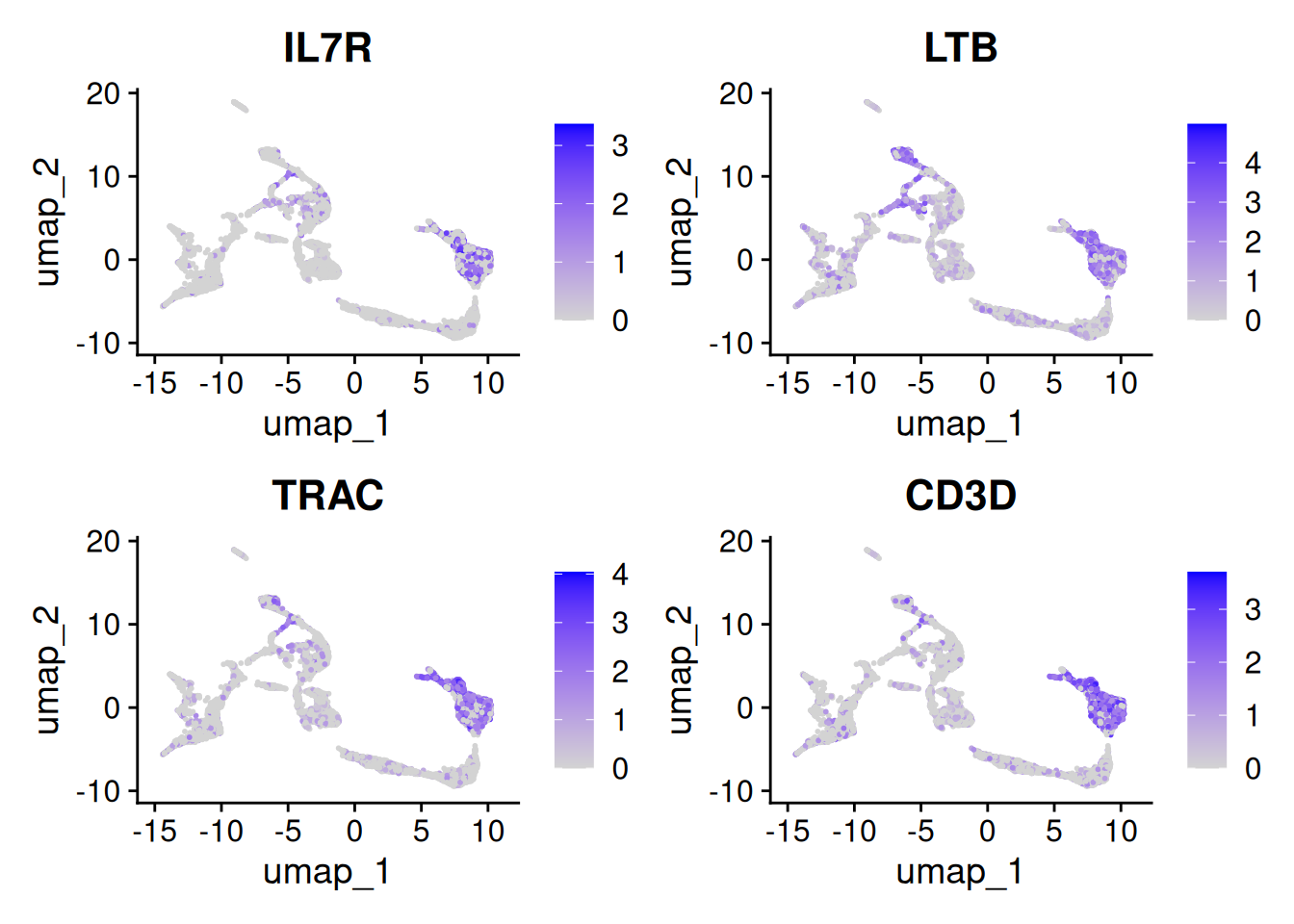
These cells are almost all in cluster 0 and 8. Which becomes clearer when looking at the violin plot:
Seurat::VlnPlot(seu,
features = tcell_genes,
ncol = 2)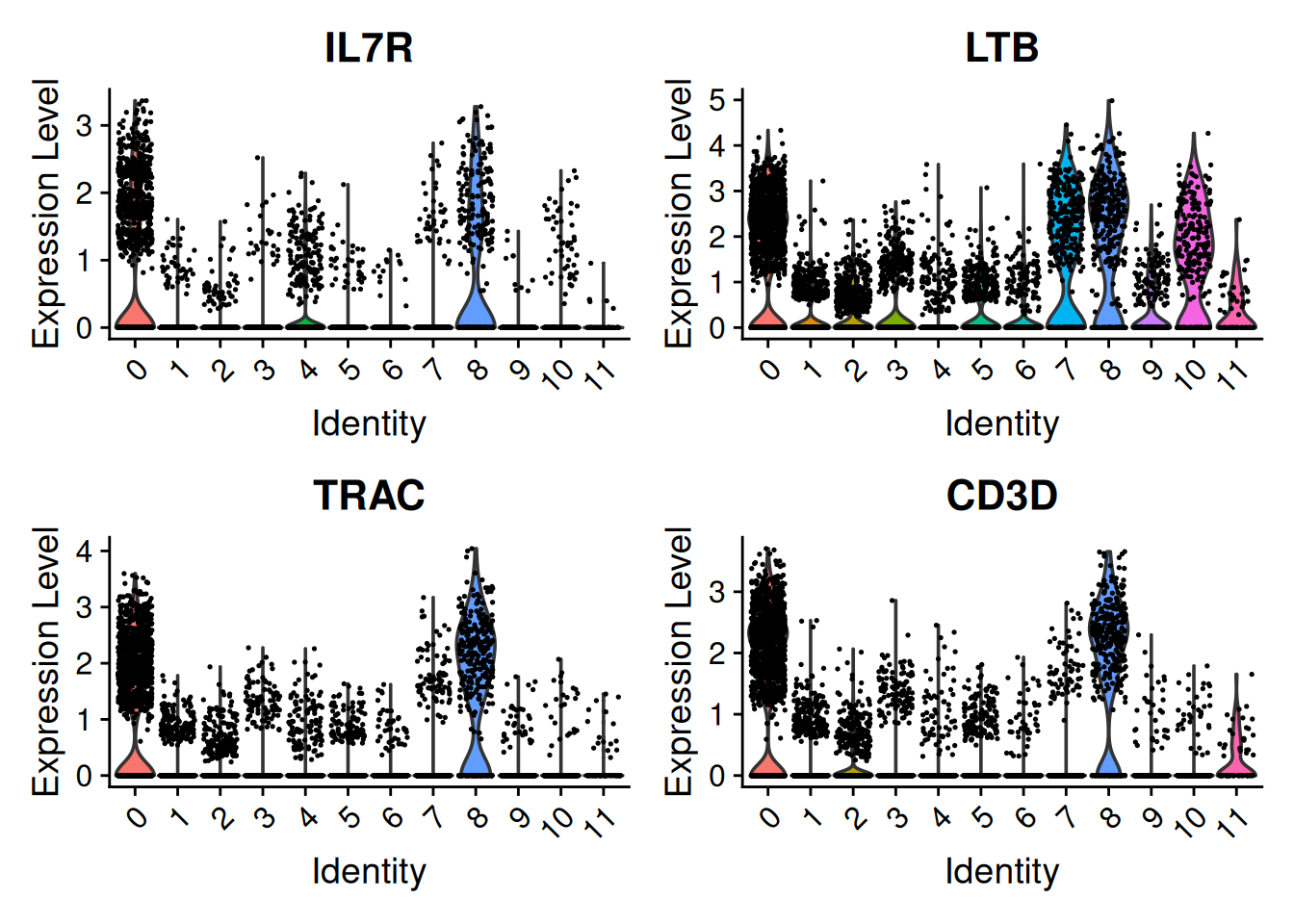
Have a look at the monocyte genes as well. Which clusters contain probably monocytes?
Seurat::FeaturePlot(seu, monocyte_genes, ncol=2)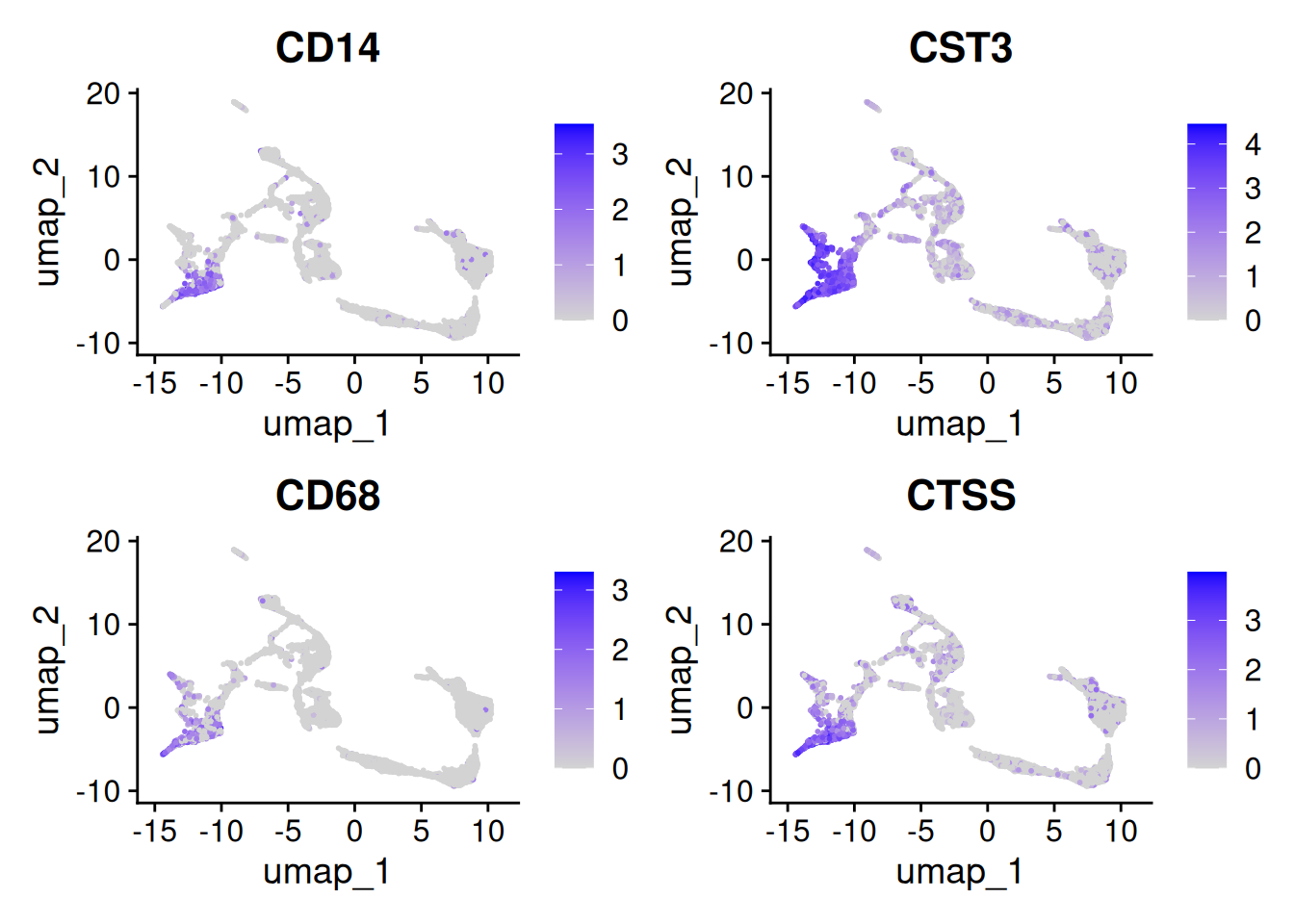
Seurat::VlnPlot(seu,
features = monocyte_genes,
ncol = 2)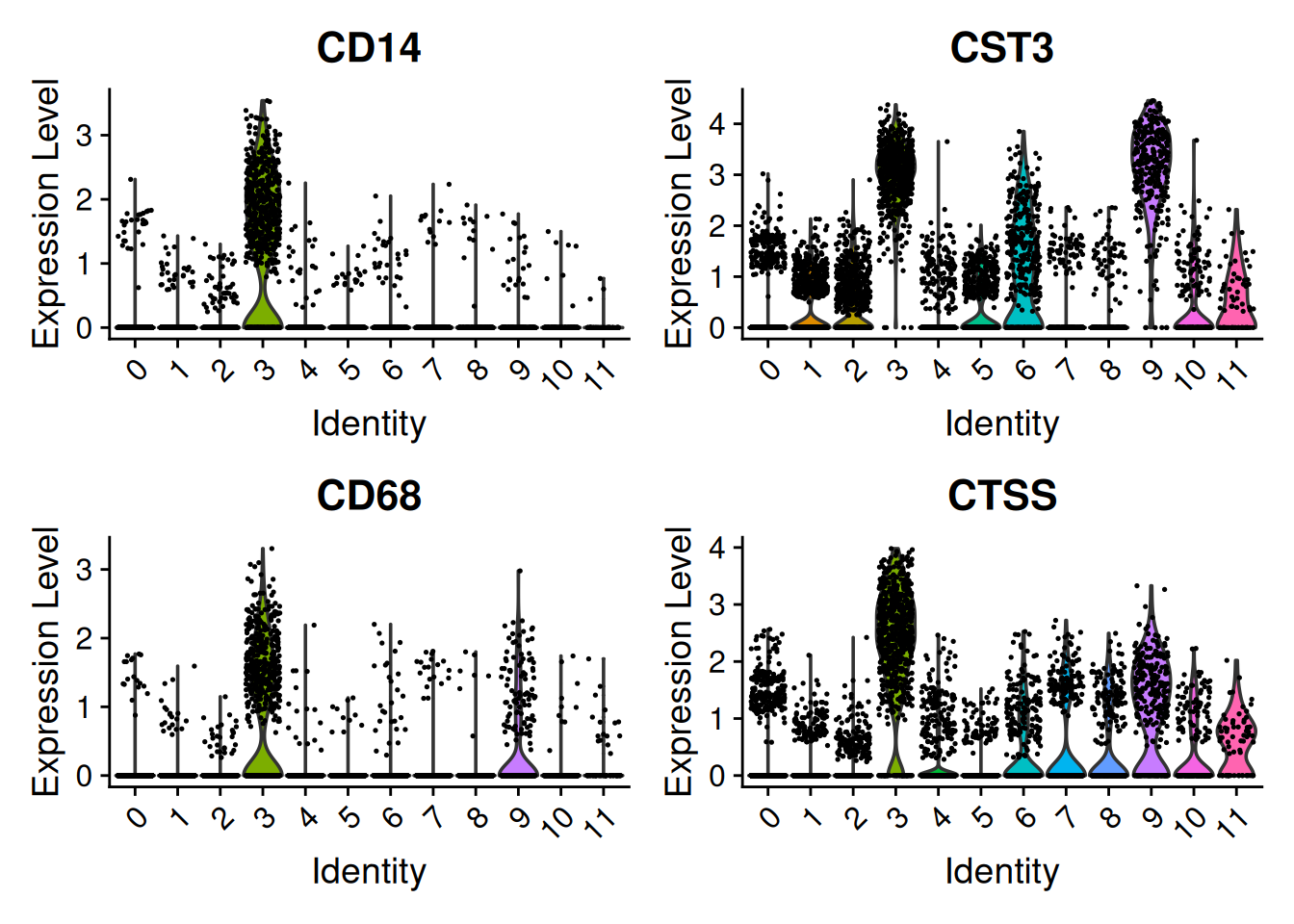
We can also automate this with the function AddModuleScore. For each cell, an expression score for a group of genes is calculated:
seu <- Seurat::AddModuleScore(seu,
features = list(tcell_genes),
name = "tcell_genes")After running AddModuleScore, a column was added to seu@meta.data.
A. What is the name of that column? What kind of data is in there?
B. Generate a UMAP with color accoding to this column and a violinplot grouped by cluster. Is this according to what we saw in the previous exercise?
A. The new column is called tcell_genes1. It contains the module score for each cell (which is basically the average expression of the set of genes).
B. You can plot the UMAP with
Seurat::FeaturePlot(seu, "tcell_genes1")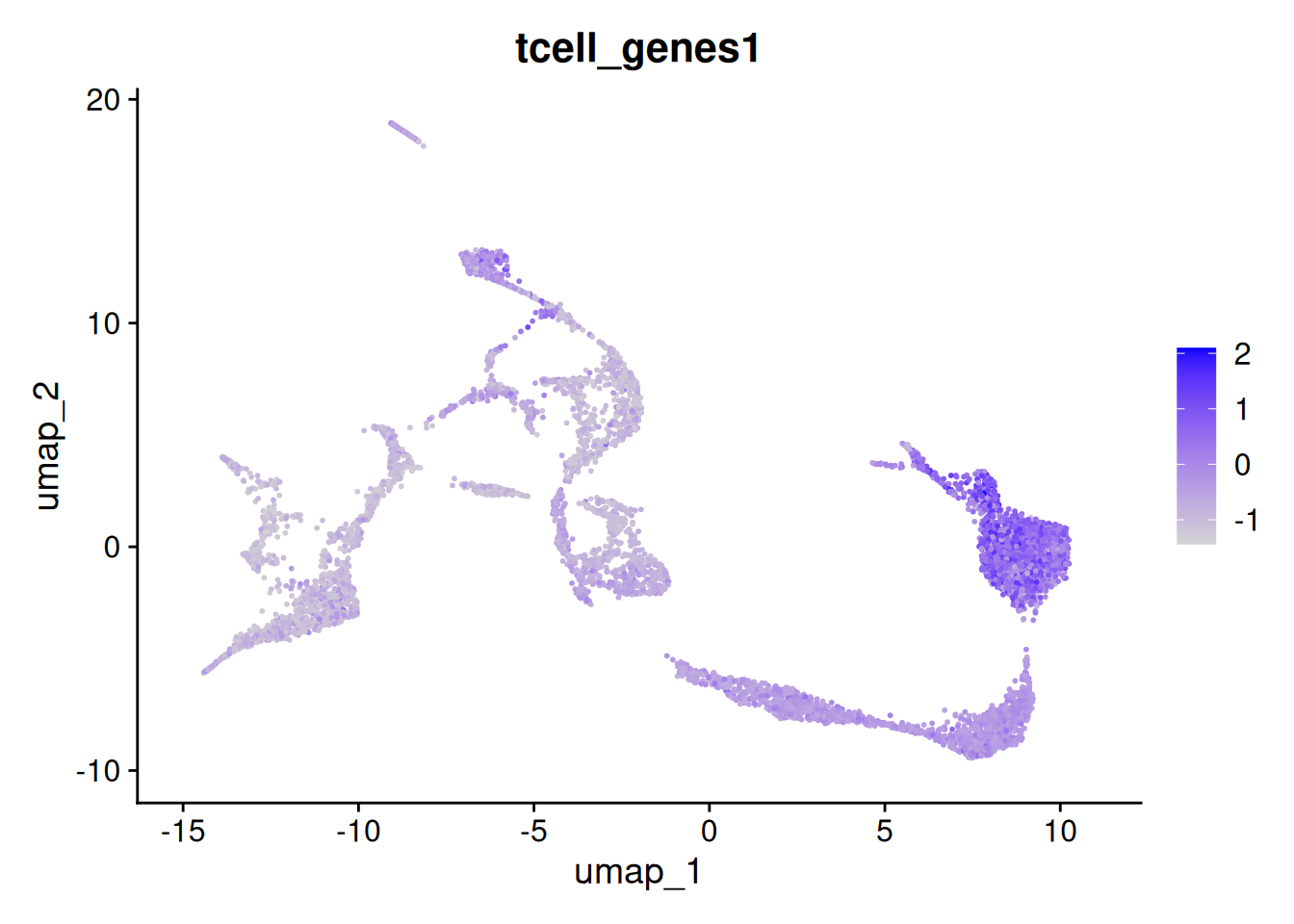
Which indeed shows these genes are mainly expressed in clusters 0 and 8:
Seurat::VlnPlot(seu,
"tcell_genes1")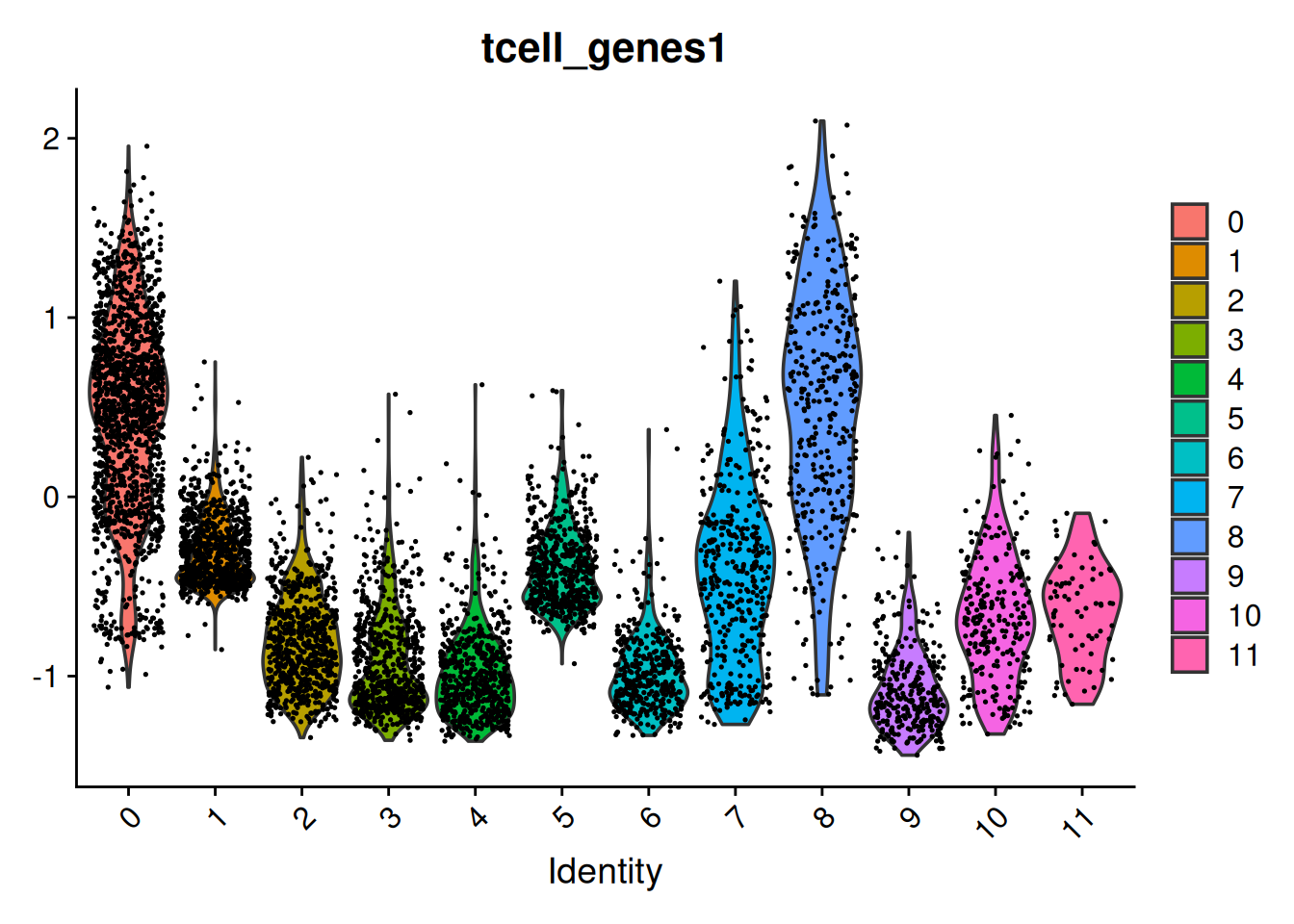
Annotating cells according to cycling phase
Based on the same principle, we can also annotate cell cycling state. The function CellCycleScore uses AddModuleScore to get a score for the G2/M and S phase (the mitotic phases in which cell is cycling). In addition, CellCycleScore assigns each cell to either the G2/M, S or G1 phase.
First we extract the built-in genes for cell cycling:
s.genes <- Seurat::cc.genes.updated.2019$s.genes
g2m.genes <- Seurat::cc.genes.updated.2019$g2m.genesNow we run the function:
seu <- Seurat::CellCycleScoring(seu,
s.features = s.genes,
g2m.features = g2m.genes)And we can visualize the annotations:
Seurat::DimPlot(seu, group.by = "Phase")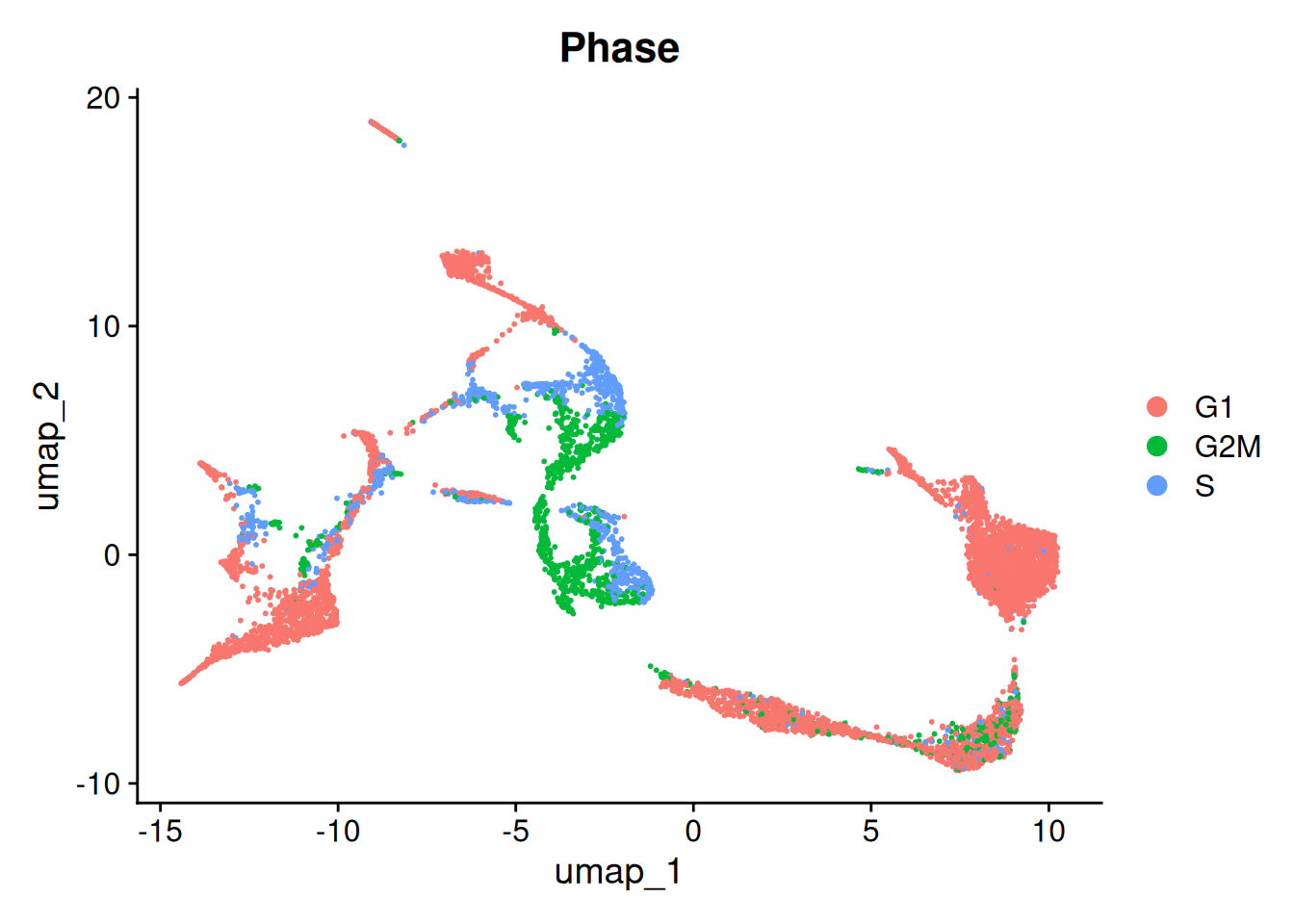
Based on your application, you can try to regress out the cell cycling scores at the step of scaling. Reasons for doing that could be:
- Merging cycling and non-cycling cells of the same type in one cluster
- Merging G2/M and S phase in one cluster
Note that correcting for cell cycling is performed at the scaling step. It will therefore only influence analyses that use scaled data, like dimensionality reduction and clustering. For e.g. differential gene expression testing, we use the raw original counts (not scaled).
Here, we choose not to regress out either of them. Because we are looking at developing cells, we might be interested to keep cycling cells seperated. In addition, the G2/M and S phases seem to be in the same clusters. More info on correcting for cell cycling here.
Cell type annotation using SingleR
To do a fully automated annoation, we need a reference dataset of primary cells. Any reference could be used. The package scRNAseq in Bioconductor includes several scRNAseq datasets that can be used as reference to SingleR. One could also use a reference made of bulk RNA seq data. Here we are using the a hematopoietic reference dataset from celldex. Check out what’s in there:
ref <- celldex::NovershternHematopoieticData()
class(ref)
table(ref$label.main)You will be asked whether to create the directory /home/rstudio/.cache/R/ExperimentHub. Type yes as a response.
You can find more information on different reference datasets at the celldex documentation
Now SingleR compares our normalized count data to a reference set, and finds the most probable annation:
seu_SingleR <- SingleR::SingleR(test = Seurat::GetAssayData(seu),
ref = ref,
labels = ref$label.main)See what’s in there by using head:
head(seu_SingleR)DataFrame with 6 rows and 4 columns
scores labels
<matrix> <character>
PBMMC-1_AAACCTGCAGACGCAA-1 0.216202:0.197296:0.086435:... B cells
PBMMC-1_AAACCTGTCATCACCC-1 0.143005:0.129582:0.170521:... CD8+ T cells
PBMMC-1_AAAGATGCATAAAGGT-1 0.113423:0.196264:0.111341:... Monocytes
PBMMC-1_AAAGCAAAGCAGCGTA-1 0.166749:0.168504:0.239303:... CD4+ T cells
PBMMC-1_AAAGCAACAATAACGA-1 0.102549:0.103979:0.178762:... CD8+ T cells
PBMMC-1_AAAGCAACATCAGTCA-1 0.181526:0.147693:0.115841:... Erythroid cells
delta.next pruned.labels
<numeric> <character>
PBMMC-1_AAACCTGCAGACGCAA-1 0.1471065 B cells
PBMMC-1_AAACCTGTCATCACCC-1 0.0753696 CD8+ T cells
PBMMC-1_AAAGATGCATAAAGGT-1 0.1274524 Monocytes
PBMMC-1_AAAGCAAAGCAGCGTA-1 0.0845267 CD4+ T cells
PBMMC-1_AAAGCAACAATAACGA-1 0.0607683 CD8+ T cells
PBMMC-1_AAAGCAACATCAGTCA-1 0.1057135 Erythroid cellsVisualize singleR score quality scores:
SingleR::plotScoreHeatmap(seu_SingleR)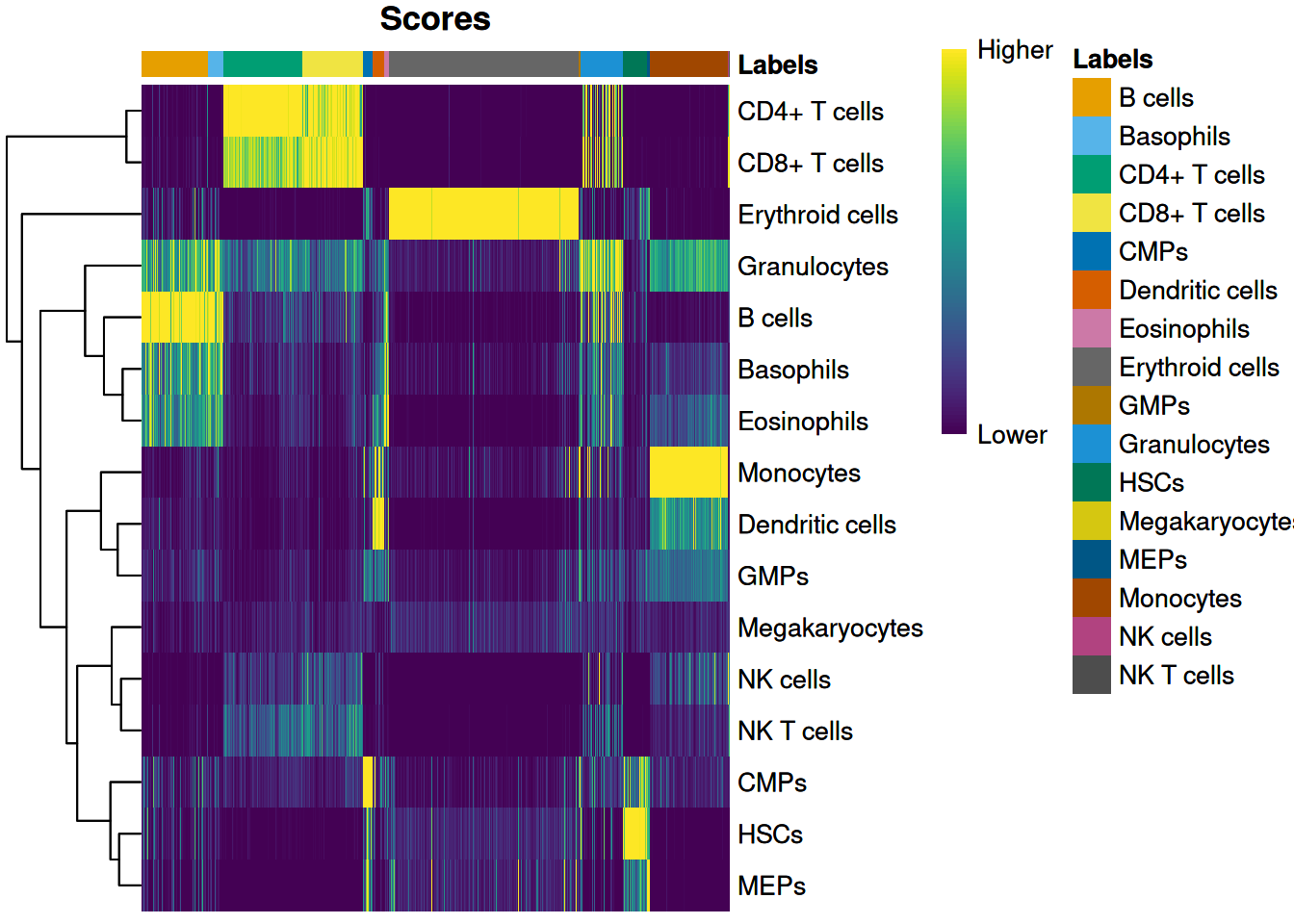
SingleR::plotDeltaDistribution(seu_SingleR)Warning: Groups with fewer than two datapoints have been dropped.
ℹ Set `drop = FALSE` to consider such groups for position adjustment purposes.Warning in max(data$density, na.rm = TRUE): no non-missing arguments to max;
returning -InfWarning: Computation failed in `stat_ydensity()`.
Caused by error in `$<-.data.frame`:
! replacement has 1 row, data has 0Warning in min(x): no non-missing arguments to min; returning InfWarning in max(x): no non-missing arguments to max; returning -Inf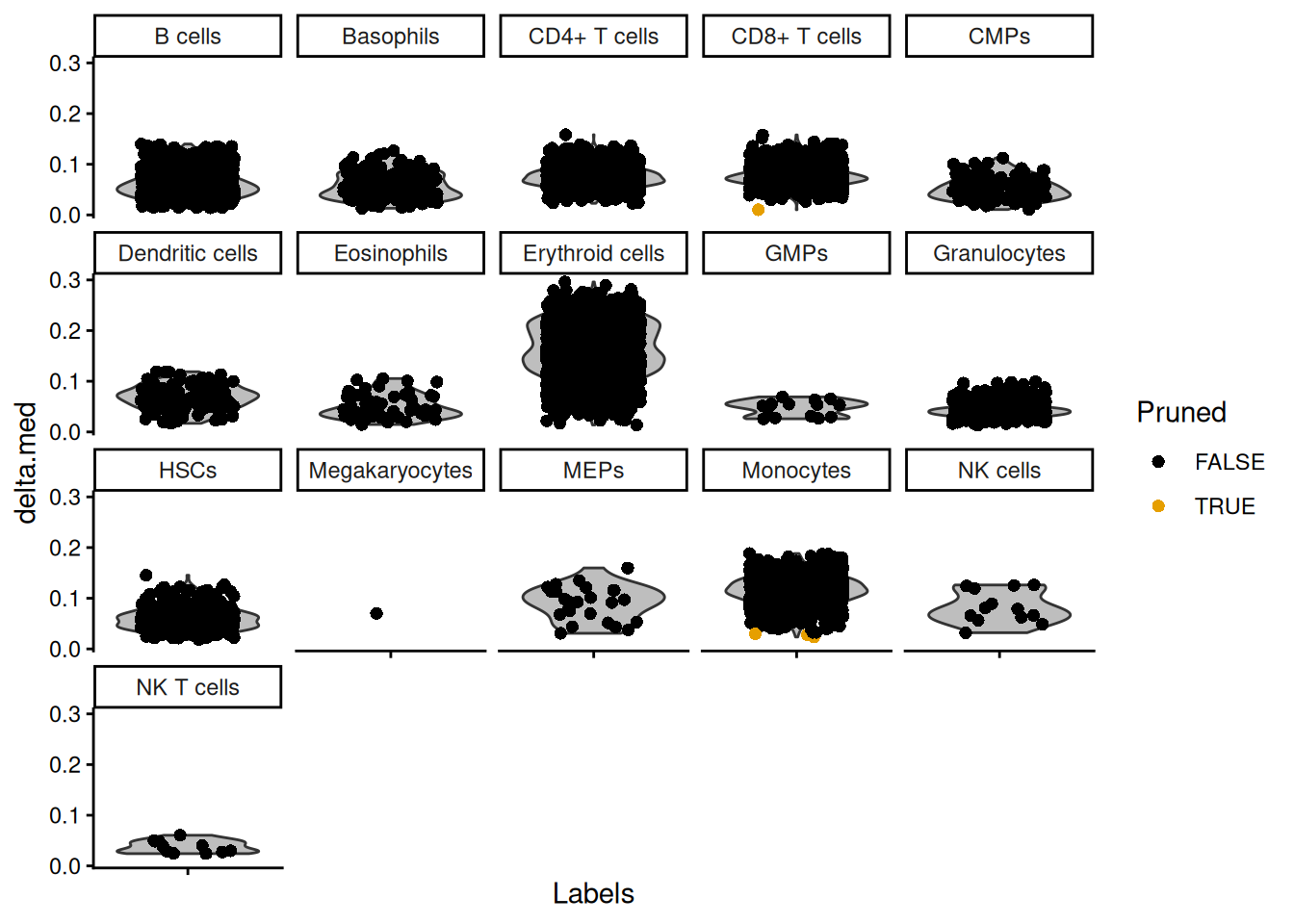
There are some annotations that contain only a few cells. They are usually not of interest, and they clogg our plots. Therefore we remove them from the annotation:
In order to visualize it in our UMAP, we have to add the annotation to seu@meta.data:
seu$SingleR_annot <- singleR_labelsWe can plot the annotations in the UMAP. Here, we use a different package for plotting (dittoSeq) as it has a bit better default coloring, and some other plotting functionality we will use later on.
dittoSeq::dittoDimPlot(seu, "SingleR_annot", size = 0.7)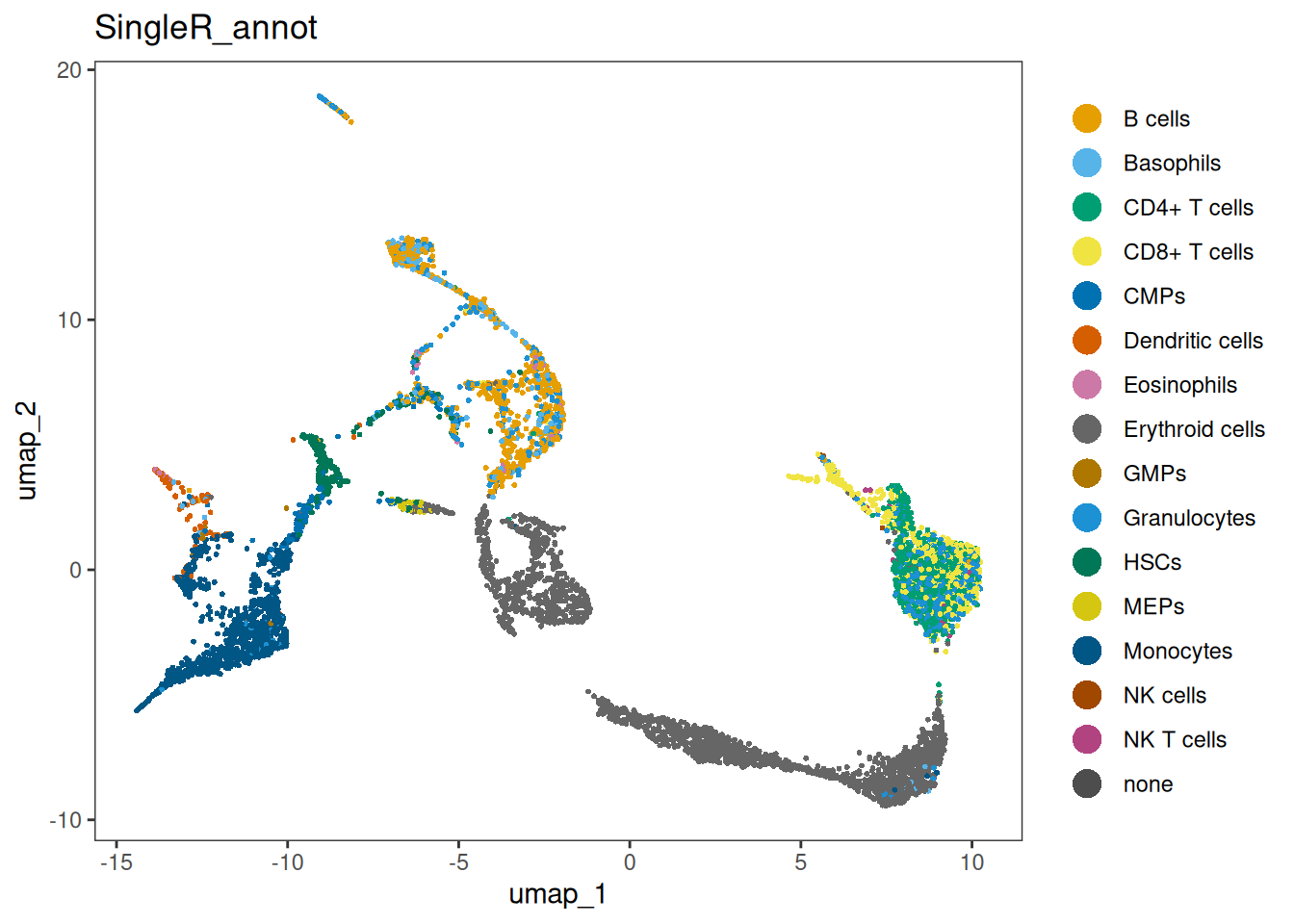
We can check out how many cells per sample we have for each annotated cell type:
dittoSeq::dittoBarPlot(seu, var = "SingleR_annot", group.by = "orig.ident")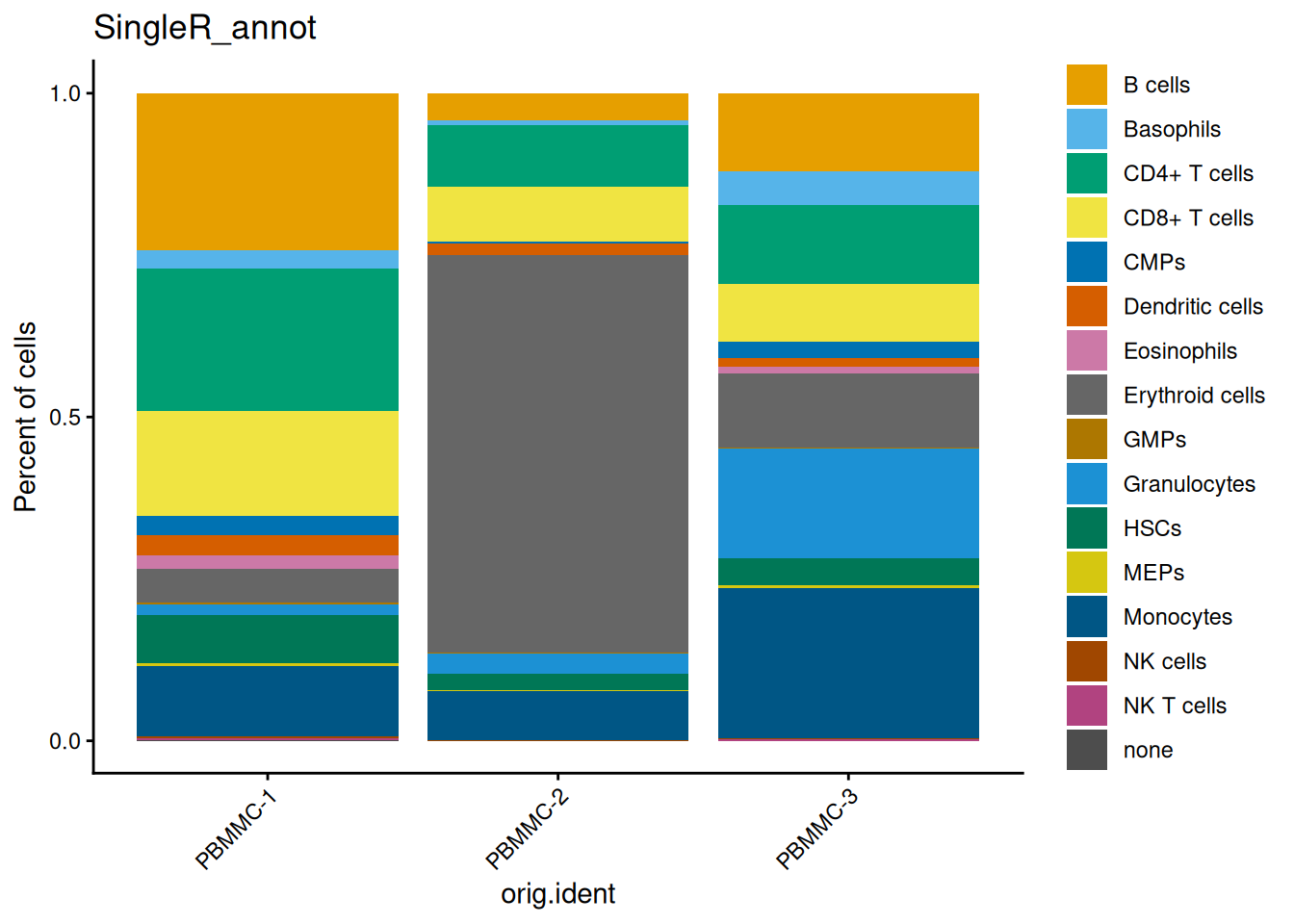
Compare our manual annotation (based on the set of T cell genes) to the annotation with SingleR. Do they correspond?
You can for example use the plotting function dittoBarPlot to visualize the cell types according to cluster (use RNA_snn_res.0.3 in stead of orig.ident))
We can have a look at the mean module score for each SingleR annotation like this:
dittoSeq::dittoBarPlot(seu,
var = "SingleR_annot",
group.by = "RNA_snn_res.0.3")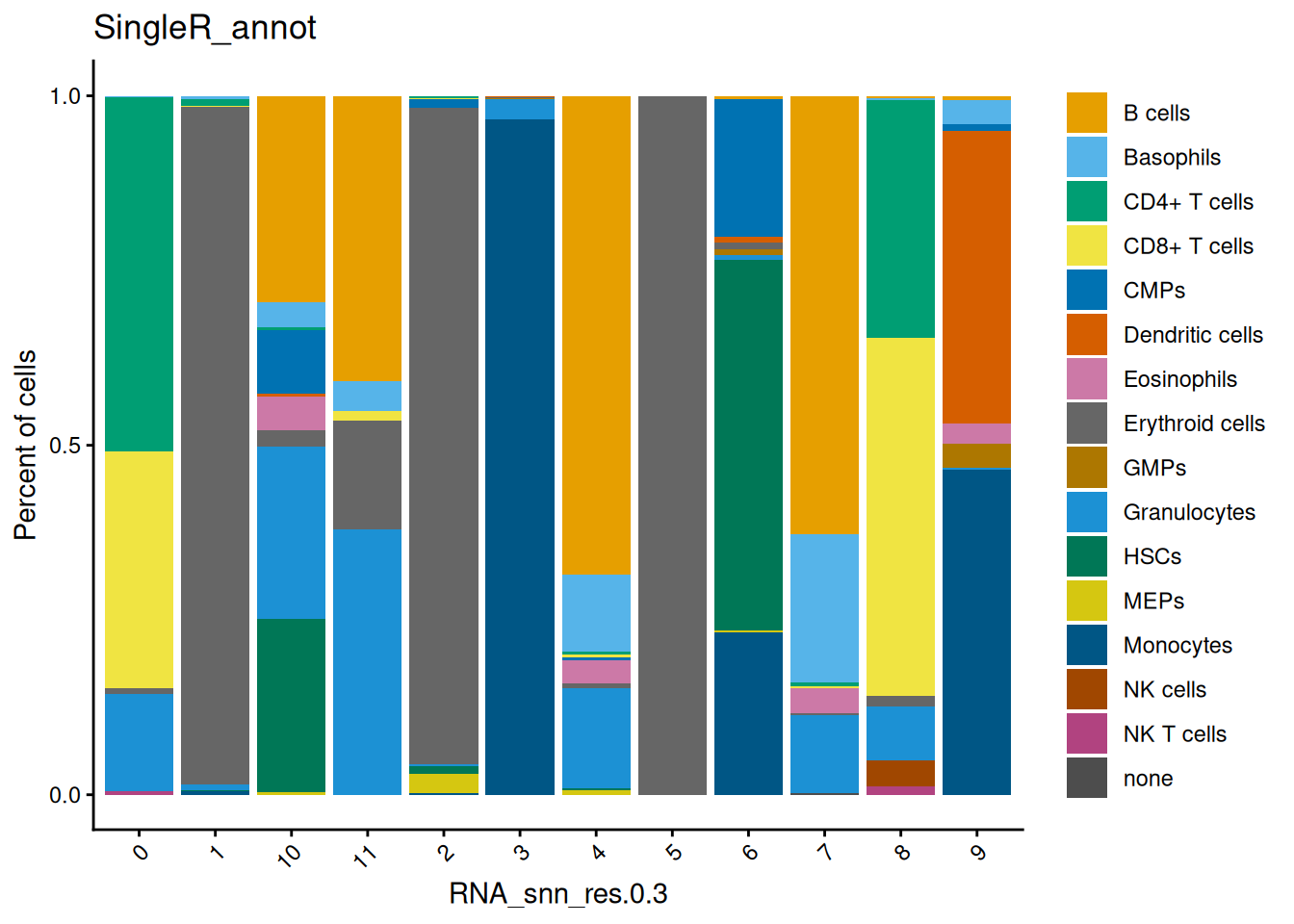
Here, you can see that cluster 0 and 8 contain cells annotated as T cells (CD4+ and CD8+).
Save the dataset and clear environment
Now, save the dataset so you can use it tomorrow:
dir.create("day3")Warning in dir.create("day3"): 'day3' already existssaveRDS(seu, "day3/seu_day3-1.rds")Found more than one class "package_version" in cache; using the first, from namespace 'SeuratObject'Also defined by 'alabaster.base'Found more than one class "package_version" in cache; using the first, from namespace 'SeuratObject'Also defined by 'alabaster.base'Clear your environment:
gc()